User requirements are oftentimes expressed in natural language, especially in the early phases of a project, and this fact has led many practitioners into believing that requirements management is a simple activity. It is so simple, they think, that all one needs to do is to write them down once and for all at the beginning, and go straight to the realization phase.
We are so used to natural language that when we write requirements, we sometimes forget that good requirements must have certain qualities like consistency, completeness, and computability, to name a few. But these concerns are usually ascribed to the realm of more formal specifications and are otherwise often neglected.
Overlooking the complexity of requirements management could be seen by some as a “philosophical topic”, with the implied negative meaning that it is purely theoretical and it does not have practical consequences. But this opinion, as it happens, is fairly wrong. It is wrong because, as everyone with experience knows, it is particularly difficult to fix requirements mistakes in later phases of a project, and the implied costs increase very fast.
This essay is aimed at giving a high-level overview of requirements management, with a focus on those aspects which can help clarify some of the most commonly held and, sadly, dangerous misconceptions on this delicate topic. First, a definition of user requirements is given. Next, the concept of requirements elicitation is introduced. After that, I will introduce Requirements Analysis and I will briefly touch on Requirements Engineering. These elements will allow me to progress with the explanation of the paradigm shift from sequences of project phases to iterations. In the conclusions I will summarise some consequences of this essay, in terms of misconceptions disproved.
Before I proceed, I would like to give a formal definition of what I mean exactly when I use the term user requirements.
What are User Requirements
User requirements are statements expressing desired qualities of a system to be realised. They are the primary means of describing what the system shall do, and how it shall behave. Requirements can be expressed by people representing different viewpoints, and this reflects in their granularity and content. There can be general requirements, described in terms of business objectives to be achieved, services to be activated or revamped, and so on. This class of requirements is typically articulated by sponsors. A sponsor is someone who has a problem to solve, and is ultimately accountable for it. But there can also be other kinds of requirements, expressed by different stakeholders[1], from their specific viewpoint. The granularity of such requirements varies, and ranges from technical requirements to security requirements, legal requirements, availability requirements (SLA[2]s) and so on and so forth. All viewpoints are relevant for the successful realisation of the requested system.
Requirements Elicitation
“Over the years we have fooled ourselves into believing that users know what the requirements are and that all we have to do is interview them. It is true that the systems we build should support users and that that we can learn about user interaction from the users themselves. However, it is even more important that systems support the mission for which they are built”[3].
The fact that someone has a problem to solve does not imply in any way that they be able to articulate it, writing, for example, a requirements document. The reason is simple: writing requirements is already a first step in the solution space, and someone with a problem, oftentimes does not have a clue how to solve it. There can of course be exceptions but, as a general rule, one must be prepared to be confronted with initial requests which are rather unqualified and imprecise. This implies that requirements engineers should not be passive receivers of someone else’s requests, but be actively involved in their definition. This is why in the literature the expression “requirements elicitation” recurs. What does that mean? It means that gathering requirements is more like an interactive interaction than a static exchange of information. The difficulty in clarifying and interpreting written requests is familiar to everybody who has ever been part of one of those never ending e-mail exchanges. Dozens of replies are quickly generated until eventually there is so much confusion, that the only viable option remains a face-to-face meeting with the relevant counterparts. When it comes to discussing user requirements, a similar communication pattern applies. Hence, requirements cannot be simply gathered, or written. They need be elicited. To sum up, requirements elicitation is the process whereby an initial high-level request is iteratively improved adding details, completing missing parts, resolving ambiguities, and renegotiating unsatisfiable wishes. Such process requires two parties: a stakeholder and a requirements engineer. The ability of the requirements engineer is to be able to put the stakeholder in a position to express with clarity their viewpoint. In this respect, it is important to notice that requirements elicitation cannot be done focussing exclusively on the logical level. This can of course be useful for the identification of general gaps. But if one is to pursue truly successful requirements elicitation, a deep understanding of, and experience with the class of systems to be realised is necessary. Contrary to what some may think, there is little room here for generalists. Which is the reason for this? The reason is such a thing as implicit requirements.
Implicit Requirements
When one has to specify the attributes of a system, the description must end at some point. One must be given the possibility to give some obvious truths for granted. Naturally, the fact that some things may safely remain unsaid, or unwritten, is dependent on several strict conditions. For example, the fact that the requested solution belongs to a category of systems, having a well known set of general qualities. So common and very well known within a cultural group, that they can be safely left implicit. If one buys a car, the fact that there be a steering wheel, or seats, or what have you, is a safe assumption. It would not be as safe an assumption if one were to specify the requirements of a car like the one you and I drive every day, to a visiting Martian. But Martians are not the only group one can imagine having a different cultural bias than one’s own. There is clearly no scientific way to pre-determine what is the degree of cultural affinity between the requestor and the requirements engineer. Hence, there are no golden rules concerning the determination of what can be safely left unsaid. Except one. Ask, ask, ask. If the requirements engineer is knowledgeable about the solution domain, she can elicit the specification of the things unsaid which can make a difference. Elicitation is all about posing the right questions. The requestor may not even be aware of the existence of certain qualities, or may simply give it for granted that the engineer was sharing her judgement in specifying them. Let us consider the case of someone wanting to buy a car, say John. John goes to a nearby car seller and asks for a comfortable car with an automatic gear. He adds, his favourite maker is “ABC”. The salesman, say Derek, asks: “Which kind of gear would you like”. John: “An automatic one”. Derek: “I see. If you prefer a sporty gear, I advise you to consider a double clutch. If you like a more relaxed driving experience, you could go for a traditional gear with torque converter. ABC allows you to choose either one”. John: “In this case I prefer a traditional automatic gear.”
In this example, had not Derek asked John the question about the kind of automatic gear, John would not have had all the elements to make an informed decision. It was clearly not his fault neglecting to specify this detail. He was simply unaware of the existence of these two distinct kinds of automatic gear, even though he was absolutely in clear about his wish to drive a car with automatic transmission. Derek’s question has allowed John to ponder how to best qualify his request, and to make it more aligned to his actual wish. Could a good requirements engineer without car knowledge have done as good a requirements elicitation as Derek’s? You judge. Admittedly, the example above might seem far fetched. But if we consider a question like “Would you like the new system to connect to the existing user registry, or to use its internal one?”. This may sound more familiar. And in the same way as John need not be a car expert to buy a car, a project sponsor need not be an expert in LDAPs to require a new CRM.
Requirements Analysis
In the initial phase of requirements elicitation, the best way to formalise user requirements is to use natural language. Such a choice has several advantages. First, it allows for ease of understanding by a broader range of stakeholders, which may not have an education in formal systems or languages. Second, it shortens revision cycles with diverse stakeholders, making it easier to reach consensus. The downside, on the other hand, is ambiguity. Requirements elicitation can actually detect and fix only part of the inconsistencies or ambiguities, because its focus is more on completeness. Consequently, after the requirements have been elicited, it is necessary to carefully analyse them, and clarify all the sources of equivocation. Requirements analysis is aimed at translating the initial specification of qualities into a clear, consistent, and realistic description of the desired system.
Requirements analysis is a delicate step and encompasses several aspects, including:
- delimiting the perimeter of the system to be realised
- detecting and resolving ambiguous statements
- assessing the overall consistency of the desired qualities
- determining the existence of a computable solution to the request
Understanding the boundaries of the solution is a fundamental way to reduce risk and manage expectations. Systems do not exist in the vacuum, they are embedded in an environment composed of other technology artifacts and human beings. The solution is likely to require interaction with some of them, and delimitation of its perimeter helps identify with precision the interfaces.
Natural language, different than computer languages, is ambiguous, and that is both its beauty and the main constituent of its expressiveness. It is indeed unfortunate that, when it comes to budgets and schedules, the results of a misunderstanding or semantic ambiguity is a lot less fascinating or, sometimes, even funny, than in other contexts like human relations or poetry. An unclear requirement is very likely to cause delays, budget overruns, unrealistic expectations and, in some cases, loss of jobs. For these reasons, clarification of user requirements is probably the wisest thing a requirements engineer can do. Since misunderstanding of requirements tends to generate a snowball effect, timeliness is key to resolving a dangerous situation before it is too late to mitigate its consequences.
Requirements express wishes and, as such, may suffer from the inconsistencies of all things human. Inconsistencies may be apparent or intrinsic. In the former case requirements express qualities which are sometimes irreconcilable, but not in the particular case at hand, where they can actually be pursued. An example follows. Let us assume a manager requested the following requirement to the hiring agency: “I would like to hire software engineers with outstanding productivity, able to write software with very few defects”. High productivity is oftentimes accompanied by poor quality, and this happens in so many cases that one may be tempted to assume it is also true for software engineering. However, studies reveal that it is not quite so. Actually, the most productive engineers write software with less defects[4]. In the latter case, that is, intrinsic inconsistency, there is little else to do than renegotiating the requirements with their author. With luck, the negotiation succeeds, and a fixed version of the requirement document is released. In the worst case, the negotiation fails, and it is necessary to escalate the problem. Ultimately, if a request persists which is unsatisfiable, the best thing to do is to decline the assignment. If the requirements engineer is not in a position to do so, this can easily translate in a very dangerous situation, in which a project team is held hostage in pursue of an impossible dream, that is bound to be hugely expensive.
When ambiguities are resolved, the perimeter of the solution is defined, and the consistency of requirements is assessed, one may be tempted to think everything crucial has been taken care of. However, that is not always the case. The reason is that solutions based on software artifacts require the existence of an algorithm capable of solving the problem described by the requirements. If one thinks about such beautiful pieces of software engineering as Adobe Photoshop, Google Maps, search engines, avionic applications, or artificial intelligence, it could seem that everything is theoretically possible in software. However, this popular belief is deeply mistaken. What a computer, or automaton of any present or future kind, can do, is execute computable functions. At this point, some readers will ask themselves, are not all functions computable?. Well, the answer is a definite no. The explanation of this important result may result difficult for those readers new to mathematical logic, but the important thing to grasp is only its essence, leaving details to professional mathematicians or philosophers. The fact remains, not all problems admit of an algorithmic solution, and with this important truth, the requirement engineer needs to familiarise herself.
For those willing to know more on this, I will briefly sketch the argument. The details are very well presented in mathematical logic books[5]. The following argument can be skipped without compromising the understanding of the remainder of this essay.
The argument starts with the definition of what is an effectively computable function:
A function is effectively computable if there are definite, explicit rules by following which one could in principle compute its value for any given arguments[6].
Mathematician and father of computer science, Alan Mathison Turing, introduced an idealised computing machine, named after him: the Turing Machine. The formal definition of such an automaton (which I omit here for the sake of simplicity) easily shows that all Turing-computable functions are effectively computable; Turing’s thesis is that all effectively computable functions are Turing-computable [Boolos et al; 2003; page 33]. Consequently, if Turing’s thesis holds true, a function is effectively computable if-and-only-if it is Turing computable. An essential property of the set of all Turing machines is that it is enumerable. This intuitively means that there are as many Turing machines as there are natural numbers. Which means infinite, but of a kind of infinity which is of a lesser degree than the infinity of all definable functions, computable or otherwise[7].
This is a remarkable result, because it brings to the philosophical consequence that human beings are able to define infinitely more problems than the ones which admit of an algorithmic solution. One could object that even though this may be an amusing, if weird, topic of mathematical logic, the practical consequences on requirements elicitation are close to null. However, there is no evidence whatsoever that all non-computable functions need be devoid of practical interest[8]. For all we know, we may be subject to an amazingly high number of requests, for which no computer program can implement a solution. The bottom line is that, when confronted with user requirements, one must be careful before saying the fatidical “yes, we can do it”.
Requirements Engineering
Once requirements have been clearly articulated and their elicitation has reached an advanced state, requirements engineering begins. This process is about translating descriptions of qualities expressed in natural language in a more structured way, with the intent to come closer to the precision and clarity of a mathematical description. In other words, requirements engineering is aimed at filling the gap between the world of humans and the world of automatons. The link between these two distant worlds, the means of bridging these apparently irreconcilable ontologies, is Use Case analysis. The term Use Cases is now very popular, and it is used in many ways. However, contrary to what too many practitioners nowadays believe, it is not a general term anyone can use light-heartedly. It is a technical term first defined with precision by Dr. Ivar Jacobson in his seminal book “Object Oriented Software Engineering”[9]. Other uses of the term only contribute to creating unnecessary confusion with which recent literature is all too often plagued. This essay does not aim at giving yet another explanation to what is Use Case analysis. Excellent sources abound[10]. Practical approaches have also emerged which can bring a lot of added value to the requirements engineer practitioner. Most notably, web site http://www.volere.org provides a comprehensive collection of resources, ranging from a thorough requirements specification template, to business analysis resources.
In the remainder of this essay we will see how, in reality, the steps described above do not occur in an ordered sequence of steps. Actually, they are part of an iterative cycle. This fact has been recognized relatively recently, and its past neglect has been source of much distress and failure in project management practices.
From Sequences to Iterations: the Paradigm Shift
In the early days of methodologies, a commonly-held belief was that requirements can and should be fixed at the beginning of a project, and rarely, if at all, amended in subsequent phases. The rationale for this was that, on the one hand, there was a superficial and simplified understanding of how humans interact in real life, and, on the other hand, changes in requirements were ascribed as one primary cause for project failure in terms of budget overruns or missed deadlines. Several influential authors in the area of methodologies had an engineering background and applied concepts derived from formal methods to modelling of communication between persons. With this unambiguous but simplistic semantics of human-to-human communication, gathering requirements was conceived of as little more than passing a message from stakeholder A (the requestor) to stakeholder B (the requirements engineer[11]). This message-exchange metaphor was reflected in the most influential method of the time: the Waterfall method introduced by Winston Royce in the seventies. A high-level view of this model is provided below.
The picture above clearly shows that the definition of requirements was intended as the first phase of a project, on which all that was to come next had to rely, with religious faith on their absolute correctness. The assumption was that, if requirements are correct, the design will also be correct and, therefore, also the implementation. Certainly, the economic context of the seventies was less volatile than it has become in the subsequent age of the information revolution and the economic crisis. Even so, the assumption that the external context could be considered frozen once the requirements had been formally accepted, was doomed. The fact is that requirements are not mathematical axioms, existing in the pure and incorruptible world of ideas. Requirements are things human, and like all things of this kind, they are informed by the context in which they have been defined. The consistency of a set of requirements is of course a desired attribute, because without it, one could never do such a thing as project management. However, this desired stability can only be achieved in practice, over relatively short periods. The reasons vary, and may, for example, include:
- changes in constraints
- changes in macroeconomic context
- new technology options become available, which impact the solution
- technology or approach chosen prove not up to expectations
- competitors make an unexpected move
- increased awareness of the business objectives
- change of priorities
In recognition of the need for a cyclical renegotiation and re verification of initial requests and assumptions, more recent methods have introduced the concept of iterations. The Unified Method is an example of a thorough process which embodies the concept of iterative-incremental development. Such a method was first described in [Jacobson et all; 1998]. The picture below shows that requirements are dealt with not only during project inception, but also in all subsequent phases.

http://en.wikipedia.org/wiki/File:Development-iterative.gif (accessed on 26 May 2013)
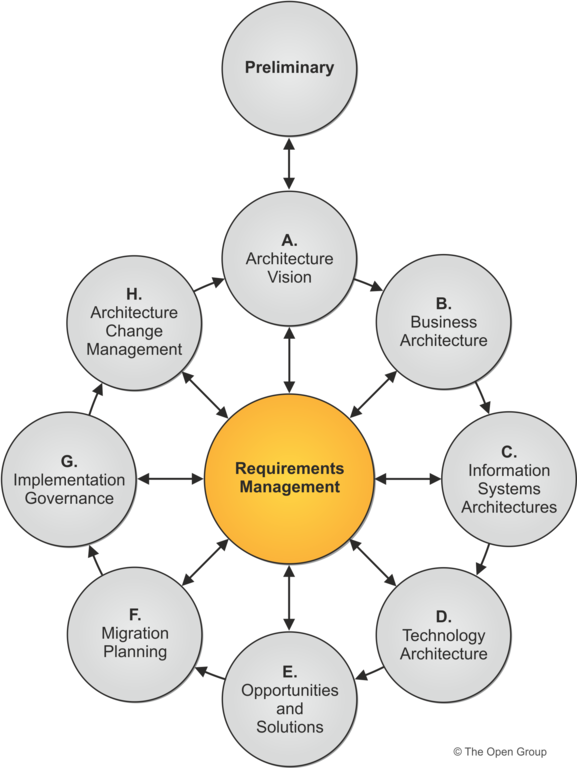
There is of course more requirements engineering in the first project phases, but adjustments take place all the way through the transition phase. This model is a lot more realistic and is based on a deeper understanding of the dynamics of communications between stakeholders during the project life-cycle. A further evolution in the understanding of the requirements life cycle is embodied in TOGAF ADM (The Open Group Architecture Framework Architecture Development Method).
The TOGAF ADM is centered around requirements management, and emphasizes the separation of concerns which is typical of the distinct phases of the architecture life cycle. The strength of this method is that, contrary to its predecessors, it makes the cyclical nature of requirements explicit, and accounts for the cultural aspects of an enterprise, which before the emergence of TOGAF have traditionally been neglected. The import of this innovation is evident if we consider that oftentimes, what determines the viability of an option, and what are the constraints to the solution space, are to be found more in the history and culture of an enterprise, than in the requirements document.
In recognition of the criticality of these aspects, TOGAF gives them first class attention, to the effect that an architecture principles document is in the list of defined architecture artifact to be produced prior to proceeding with the solution design. The existence of artifacts like the architecture principles document, contributes to the formal specification of otherwise implicit requirements, making them relevant for the development of enterprise architecture. This explicitation of cultural aspects has the beneficial effect of reducing risk, because the overall consistency of the requirements can now be checked against an augmented requirements specification, dramatically reducing the need for making assumptions. As everyone knows, excessive use of assumptions is a symptom of scarce information, and is a primary source of risk. Less assumptions, less risk.
Conclusions
Requirements Management is oftentimes overlooked as a simple activity, which can easily be settled once and for all at the beginning of a project. In actual fact, it is not like this at all. As we have seen in this essay, commonly held beliefs are plagued with dire misconceptions, which are a primary cause of much failure and distress among project management practitioners and architects alike. Among all, I will recap the two main misconceptions disproved above:
- Misconception nr 1: Everything can be done in software
- Misconception nr 2: Since changes in requirements are a reason for project failure, the only way to avoid the problem is to define them once and for all, and never change them to the end of the project.
Bibliography
Boolos et al; 2003 Boolos G. S., Burgess J. P., Jeffrey R. C. “Computability and Logic”, 4th edition, Cambridge University Press, 2003, ISBN 0-521-00758-5.
DeMarco and Lister; 1999 DeMarco T. and T. Lister. “Peopleware. Productive Projects and Teams”. Dorset House Publishing. 1999. ISBN 0-932633-43-9
Jacobson et al; 1993 Jacobson I, Christerson M., Jonsson P. and Övergaard G. “Object-Oriented Software Engineering: A Use-Case Driven Approach”, Reading. MA: Addison Wesley Longman, 1992, (Revised 4th printing, 1993).
Jacobson et al; 1998 Jacobson I, Booch G., Rumbaugh J. “The Unified Software Development Process”, Addison Wesley Longman, 1998, ISBN 0-201-57169-2
[1] “Stakeholders are anyone who has an interest in the project. Project stakeholders are individuals and organizations that are actively involved in the project, or whose interests may be affected as a result of project execution or project completion. They may also exert influence over the project’s objectives and outcomes.” [https://en.wikipedia.org/wiki/Project_stakeholder; accessed 24 May 2013]
[2] Service Level Agreements
[3] [Jacobson et al; 1998; p. 112]
[4] [DeMarco and Lister; 1999; p. 47]
[5] “Computability and Logic”, 4th edition, G. S. Boolos, J. P. Burgess, R. C. Jeffrey, Cambridge University Press, 2003, ISBN 0-521-00758-5.
[6] [Boolos et al; 2003; p. 23]
[7] It can be proved that the set of functions from positive integers to positive integers is nonenumerable. [Boolos et al; 2003; page 35]
[8] For the interested reader, I recommend reading the explanation of the “Halting Problem” . [Boolos et al; 2003; pagg. 35-40].
[9] [Jacobson et al; 1993]
[10] For instance [Jacobson et al: 1998]
[11] In those years, the term used was “Business Analyst”.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
![[Wikimedia], accessed on 26 May 2013](http://en.wikipedia.org/wiki/File:Waterfall_model_%281%29.svg){kind=link}
{kind=link}
{kind=link}