
[Wikimedia, 2015]
Application Testing is about determining whether or not a given software “behaves” as expected by its sponsors and end users. These stakeholders have a legitimate right to their expectations, because the system should have been engineered with the objective to satisfy their requirements. The diagram below represents the testing process as a black-box: 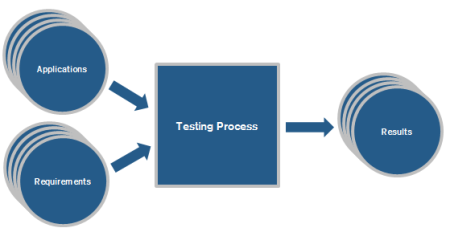 In consideration of the above, it is easy to see that Application Testing is a particular instance of a more general mathematical problem: Hypothesis Testing. As such, it can be tuned to maximise its reliability either in terms of false positives or false negatives, but not both.
In consideration of the above, it is easy to see that Application Testing is a particular instance of a more general mathematical problem: Hypothesis Testing. As such, it can be tuned to maximise its reliability either in terms of false positives or false negatives, but not both.
- False Negative: this is the error in which one incurs when a buggy application wrongly passes a test.
- False Positive: this is the error in which one incurs when a correct application wrongly fails a test.
This is a very well-known problem, and it finds application in other domains, including statistics and medicine.
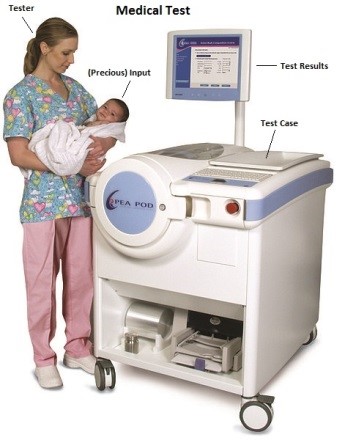
Adapted from [Wikimedia, 2015]
Let us consider, for instance, the case of medical tests. How did the scientific community manage to strike the right balance between sensitivity and reliability? In order to answer this question, one has to answer a preliminary one: what is worse, wrongly detecting an illness or failing to detect it? Clearly, the latter case is the worst. Failing to detect contagion can result in rapid spread of infectious deseases, loss of lives, and high healthcare costs. For this reason, medical tests are designed to minimise false negatives. What is the downside? It is clearly the cost of managing false positives. Whenever a critical infection is detected, medical tests are repeated in order to minimise the chance of an error.
Now, let us come back to our domain, Application Testing. What is the worst scenario, false positives or false negatives? If an application fails a test, but it is actually ok, costs originate because the application needs be investigated by software development and, sometimes, business users. But that is the end of it. Conversely, if an application has a severe problem which remains undetected until deployment to production, this is an entirely different story, and can result in a full range of critical consequences, including compliance breach, financial loss, reputational damage, and so on and so forth. So, in the financial sector, just like in medicine, testing must be optimised in order to minimise the chance of false negatives.
A question naturally arises: how do we fare in this regard? Where are we? Luckily, I believe, in the financial sector we are doing alright. Application Testing in this sector is clearly aligned with this risk management strategy. However, there is still room for improvement. The fact is that, as we have seen above, false positives also have a cost. Do we have to be prepared to pay it in its entirety, or can we do something to reduce it? To go on with the parallel with medicine, I shall argue that false positives, like cholesterol, come in two flavours: the good ones and the bad ones. The good ones originate because of unavoidable causes, like technical glitches, human error in test case design or execution, or even up the software life cycle, like wrong requirements or wrong understanding of user requirements. These errors are part of the game, and can only be mitigated up to an extent.
But there is another category of false positives which I think is bad, and can be reduced. Those are the ones generated because of lack of domain expertise. Techies will base their judgement on the evidence collected during test execution. But this evidence is oftentimes not self-explanatory: interpretation is required. And this interpretation can only go as far as the business domain experience of the tester. Enterprise-wide application landscapes implement very sophisticated workflows and support complex business scenarios. The behaviour of these applications changes depending on user rights, user role, client type, and many more criteria. What is actually the intended behaviour of an application, can easily be mistaken for an error.
So, what is my pragmatic recipe to cut down bad cholesterol in application testing (reduce the cost of false positives)? I believe the answer to this question is closely related to the evolution of the testing profession. Nowadays, a good test engineer is someone with technical skills, and business domain knowledge. This unique blend of skills is certainly precious and makes application testing a science and an art at the same time. But new trends are changing this. Automation is increasingly being pursued because of cost pressure, and of the need for increased agility and reliability. But automation comes with skills challenges of its own, to the effect that, as it is generally recognised, more sw engineering savvy personnel will be required in testing. And this is good. But, at the same time, once the amount of manual activity will be reduced, a new opportunity will exist to inject more business-savvy personnel in testing. The transition, the way I see it, can be represented like this:

To sum up, more automation will pursue optimisation in terms of minimisation of false negatives, whereas business domain expertise will reduce the costs of false positives. This evolution of the testing profession in specialist roles is what is required to apply the lessons learned from medical testing to application testing in the financial sector. I will be happy to receive your feedback on this admittedly unconventional view on the future of the testing profession.
References Wikimedia, 2015, https://commons.wikimedia.org/wiki/File:Infant_Body_Composition_Assessment.jpg, accessed on 24.07.2015 Morelli M, 2013, https://alaraph.com/2013/09/26/the-not-so-simple-world-of-user-requirements/, accessed on 07.08.2015





{kind=link}
{kind=link}