Introduction
What all structures of power have in common is the problem to enable a minority to rule the majority. This is a very old problem, a classical one. Different cultures have addressed it in different ways. Some using techniques of brute-force domination, others adopting more elaborated methods of mind control. The realm of modern corporations has focussed on the latter approach, taking the most effective ideas from each and every culture. In this respect, modern structures of power are pretty similar across geographies. What are these techniques? It would be difficult to give an exhaustive account, because there are so many, and they keep changing. In this essay I will introduce some ever greens, which will give an overview of some of the methods used by powerful groups to exert their control over their subjects.
The first category of mind control techniques is Language Techniques. Examples of these techniques are: Manipulative Communication, Definition and Enforcement of Official Vocabulary, and Misuse of Metaphors.
The second category of mind control techniques is Cognitive Techniques, such as the use of Why/What/How questions, Partial Truths / Half-Truths, Misuse of KPIs, Information Overload, Misuse of Variable Compensation, Misuse of Gantt Charts, and Misuse of Time Management.
The third category is Emotional Techniques, such as Foment Perpetual Fear of Losing Job, The Superman CEO, Forbid Errors, Disconnection of Personal Contribution from the Outcome, Prevent Formation of Consent, Get Creative Contribution from Consultants, not Employees, Reference Letter/Work Certificate, and Misuse of Lifelong Certifications.
We will now start this inquiry into the world of scientific mind control with Language Techniques.
Language Techniques
There is a view in the literature, according to which the use of language affects formation of ideas, and influences behaviour:
“The principle of linguistic relativity holds that the structure of a language affects its speakers’ world view or cognition. Popularly known as the Sapir–Whorf hypothesis, or Whorfianism, the principle is often defined to include two versions. The strong version says that language determines thought, and that linguistic categories limit and determine cognitive categories, whereas the weak version says that linguistic categories and usage only influence thought and decisions.”
Source: (n.d). “Linguistic Relativity”. Retrieved January 4th, 2017, from https://en.wikipedia.org/wiki/Linguistic_relativity
Based on this principle, a number of manipulative techniques has been developed.
Manipulative Communication
Manipulative Communication is aimed at obtaining something from someone through insidious techniques of control. Manipulative Communication is done by using manipulative language. A good description of manipulative language is available at: http://www.clairenewton.co.za/my-articles/the-five-communication-styles.html
I reproduce an excerpt here, for convenience’s sake [accessed on 21 December 2016]
———————————————
The Manipulative Style
This style is scheming, calculating and shrewd. Manipulative communicators are skilled at influencing or controlling others to their own advantage. Their spoken words hide an underlying message, of which the other person may be totally unaware.
Behavioural Characteristics
- Cunning
- Controlling of others in an insidious way – for example, by sulking
- Asking indirectly for needs to be met
- Making others feel obliged or sorry for them.
- Uses ‘artificial’ tears
|
Non-Verbal Behaviour
- Voice – patronising, envious, ingratiating, often high pitch
- Facial expression – Can put on the ‘hang dog” expression
|
Language
- “You are so lucky to have those chocolates, I wish I had some. I can’t afford such expensive chocolates.”
- “I didn’t have time to buy anything, so I had to wear this dress. I just hope I don’t look too awful in it.” (‘Fishing’ for a compliment).
|
People on the Receiving end Feel
- Guilty
- Frustrated
- Angry, irritated or annoyed
- Resentful
- Others feel they never know where they stand with a manipulative person and are annoyed at constantly having to try to work out what is going on.
|
Source: The Anxiety and Phobia Workbook. 2nd edition. Edmund J Bourne. New Harbinger Publications, Inc. 1995.
———————————————
Manipulative communication may be used to obtain something from other people, through canning manipulation of their thought-formation processes . How can one detect manipulative language? Luckily, there are some indicators, some words which are usually reliable markers of a manipulative communication:
- all, every, none, everyone, no one, always, never, best, worst, etc.
Examples:
“You always make silly mistakes”
“You never get it right at the first attempt”
“Are you sure this is the best solution?”
“This is the worst presentation I have ever seen”
If one wants to develop resilience against manipulative communication, the first thing to do is to learn to spot this manipulative words.
Definition and Enforcement of Official Vocabulary
Imposing use of acceptable vocabulary on others is an effective way of exerting influence on how things are perceived. One thing is saying: “I’ll give you this problem to solve, and you’ll have to complete it and resolve all impediments proactively. If the task is not done, you will pay the consequences.”; quite another is saying “I think you have the right skills for owning this challenge“. The apparent meaning is exactly the same, but the second form is malicious, because it hides the negative aspects behind a layer of shiny fresh paint. The first source of manipulation is done using “challenge” instead of “problem”. A problem exists independent of the observer. For example, finding a computationally efficient algorithm which determines if a given integer is a prime number or not. But if we call this a challenge, the fact that it can be solved is implicitly attributed to the ability of the resolver, not to the objective complexity of the problem. Calling problems “challenges” is a subtle way to put pressure on the person to whom the task is given. The second manipulation is done using the expression “to own a challenge”. The notion of ownership implies that the owner of an object can, among other things, do the following:
- refuse to receive the object
- sell the object
- donate the object
- destroy the object
- dispose of the object
- exchange the object with another one
Think about it, this is certainly true of a car, a house, a book, a pair of shoes, etc. Now the point is, can one really “exchange a task or assignment” with something else? (e.g. another task one likes best?). Can one decide to reject it? The answer is no. When a manager gives an assignment, the assignee is clearly not free to reject the assignment, if not once or twice, and then s/he is shown the door. Saying that someone who has been given a task is “owning a challenge” is a gross misrepresentation of what is going on.
Misuse of Metaphors
Metaphors are a very powerful type of figurative language. According to Merriam Webster (https://www.merriam-webster.com/dictionary/metaphor, accessed on 21 Dec 2016) a metaphor is:
a figure of speech in which a word or phrase literally denoting one kind of object or idea is used in place of another to suggest a likeness or analogy between them (as in drowning in money); broadly : figurative language
How are metaphors used to control people’s mind and behaviour? The method is based on implicitly attributing qualities to an object or notion, which it does not possess. This is achieved by replacing such an object/notion with a metaphor. The metaphor shares some qualities with the original object, but not all. The manipulation is done by tricking the audience into believing that the properties of the surrogate object/notion (the metaphor) also apply to the object/notion replaced by it. A few examples will clarify. The examples below are taken from article “Twenty business metaphors and what they mean by Tom Albrighton” (http://www.abccopywriting.com/2013/03/18/20-business-metaphors-and-what-they-mean, accessed on 21 Dec 2016)
(…)
Organisations = machines
This is another product of the Industrial Revolution, when businesses were characterised like the machines around which they were built. Applying the concept of mechanisation to human work led to things like organisational diagrams (=blueprints), departments (=components), job specifications (=functions) and so on.
All these concepts were productive in their way, but they obscured the reality of an organisation as a group of people. Unlike uniform components, people have very different abilities and aptitudes. And unlike machines, they can’t be turned up, dismantled or tinkered with at will.
(…)
Products = organisms
This metaphor is expressed in phrases like ‘product lifecycle’, ‘product families’, ‘next generation’ and so on. It draws a parallel between the evolution of living things and the way products are developed. This nicely captures the idea of gradual improvement through iteration, as well as the way in which products are ‘born’ (=introduced) and eventually die (=withdrawn) – always assuming they’re not killed off by the forces of ‘natural selection’ in the market.
One drawback of this metaphor might be the way it downplays human agency. Products and services don’t actually have an independent life, nor will they evolve independently. They are the result of our own ideas and decisions – reflections of ourselves, for better or worse.
Progress = elevation
This idea encompasses such well-worn phrases as ‘taking it to the next level’ and ‘onwards and upwards’. If we visualise this metaphor consciously at all, we might think of a lift going to the next floor, or perhaps someone ascending a flight of stairs. While ‘up’ is usually associated with ‘more’ and ‘better’ (think of growing up as a child, or line graphs), not everyone likes heights.
Careers = ladders
Thinking of careers as ladders embodies the same ‘up is good’ idea as ‘progress = elevation’. The higher up the ladder you go, the more you can see – and the more you can ‘look down on’ those below you.
Since ladders are one-person tools, there’s also an implication that you’re making this climb alone. So what will happen if others do try and join you? Will the ladder break, or fall?
More to the point, what if you reach the top and discover that your ladder was leaning against the wrong wall? Jumping across to another ladder is dangerous, so you might have to go all the way back down and start again.
A more useful metaphor in this context might be ‘careers = paths’. Paths fork, implying choice. Overtaking, or being overtaken, is no big deal. You can step off the path for a while, if you like – there might even be a bench to sit on. And while some might feel the need to ‘get ahead’, it’s clear that the most important thing is not how far you go, but whether you’ve chosen the right path for your destination.
(…)
To conclude,
Metaphors are meant to create an impact in the minds of readers. The aim of this literary tool is to convey a thought more forcefully than a plain statement would.
They are exaggerated expressions no doubt, but they are exaggerated because they are supposed to paint a vivid picture, or become a profound statement or saying.
source: http://examples.yourdictionary.com/metaphor-examples.html, accessed on 21 Dec 2016
Cognitive Techniques
Why/What/How
Most people are used to defining what are the things which are important to them. Some want to pursue higher education, others want to become rich, some want to do something good for the poor or the sick. Everyone has the chance to define what is her life strategy. I will call this kind of questions, the “why” questions. When there is a vision, and objectives are defined, one has to identify what need be done. For example, if one wants to pursue higher education she has to study hard, make sacrifices, define an area of specialisation based on her interests and abilities, and so on and so forth. I will refer to questions like these as the “what” questions. When it is clear what need be done, one has to define how each activity can be accomplished. Here it is necessary to define the details. See what is the available budget, what are the universities to target, what their admission criteria, etc. I will refer to questions like these as the “how” questions.
When one works for someone else, and that is the condition of employees, depending on her role, she has access to some kind of questions but, generally, not all. Those who define the “why” questions are the CEO and the Board of Directors. In so doing, they have to interpret the intentions and priorities given by the most important shareholders. One level down, directors and general managers usually define the “what” questions, and define what need be done to achieve the set objectives. Everyone else in the organisation, is actually dealing with “how” questions. Ordinary employees are overwhelmed by details and specialist work. The need to implement and execute “what” their directors have defined.
Dealing with people in a way that carefully filters out more interesting questions and focusses on the details of the things to do is yet another way of controlling their behaviour and ensuring they will not contribute creatively to the definition of the strategy. Their action will be constrained in well defined “tasks” which someone else has created for them. If they fail, such an outcome will be easily attributed to their action, not a wrong plan, because they do not even have visibility on anything else than their micro tasks. Ordinary employees, usually, do not have the elements to understand what is the value of what they are doing, because the ultimate objective is oftentimes shared only with a few people higher up in the organisation hierarchy.
There is a lot of rhetoric about being creative, proactive and so on and so forth. But a lot of organisations, do not really expect people to engage in “what” questions (let alone in “why” questions). All they want from their employees is that they get things done independent of the inefficiencies, politics, and oddities of their working conditions. This is what is really meant, oftentimes, by “being proactive”. The skeptics are invited to try propose a change which makes a process more efficient, or simplifies a procedure, or increases employee satisfaction. And then share the outcome of their proactive and creative behaviour.
Partial Truths / Half-Truths
Salami-technique
I learnt about this expression from a manager some jobs ago. He consciously used it to obtain things from employees, keeping them in a constant condition of dis-empowerment. The “salami-technique” consists in splitting the information necessary to understand a request and execute the tasks in small items, and only share what is strictly required to obtain the execution of tasks by individuals and teams, without giving them the context. The receivers of the “information slices” will know enough to accomplish their duties in a monkey-like fashion, without gaining any insight into what their are doing. Managers practicing the “salami-technique” pride themselves of being the only ones who see the full picture making themselves indispensable.
A variant of this technique is a misused form of the “need to do/need to know” principle. This principle is applied in security in order to reduce exposure to confidential data and reduce risk of disclosure. However, the same principle is sometimes misused to justify the practice of keeping people unnecessarily in the dark and giving them only the minimum information required to execute a task.
Information Funnel
This technique has similarities with the salami-technique illustrated above, but is systematically applied in a hierarchical fashion, reducing the information content shared, every level down the organisation. It is one way in which the why/what/how principle explained above is enforced.
Misuse of KPIs
Key Performance Indicators (KPI) may be useful in defining and measuring quantitative objectives. Several good books explain how to use them wisely. In reality, many actual uses of KPIs are misguided and aimed at manipulating teams into behaving in desired ways. The way this is done is through the exploitation of a cultural bias and equivocation. I have explained this in detail in my post The False Myth of Scientific Management, to which the interested reader can refer to. Here I will give a brief summary. KPIs are expressed in figures. Figures are associated with mathematics, which is the language of science. This association is intended to implicitly claim and evoke rigour and credibility. However, KPIs are not Science, and not even science. They are a technique. Different than observables of scientific laws, KPIs are not bound by mathematical laws which allow to describe and predict phenomena in a way which makes ti possible, for example, to know what is the precision of the estimate, say, the error function, the epsilon. Not being experimental laws, they cannot be disproved if wrong. You have to stay content with the strait faces of the holy priests of this technique, its true believers. Nothing else can substantiate the truth or significance of what is measured by defined KPIs. This is not to say the cannot be used wisely. There are many good ways of doing it described in the literature. Here, the point I want to make, is that a misguided use of KPIs (not KPIs per se) can be used to manipulate people.
Information Overload
Influential book “The Net Delusion: The Dark Side of Internet Freedom” by E. Morozov explains how totalitarian regimes which initially invested their energies in censorship, have soon learnt how to apply a cheaper and more effective technique: information overload. The traditional technique based on censorship is based on the creation and maintenance of a catalogue of forbidden content and resources. This approach was effective in the pre-Internet era, when content was produced and disseminated at lower rates, and this process happened by physical means (e.g. pamphlets, books) whose distribution and access could more easily be controlled. Nowadays, maintaining a black list of undesired content is pretty impossible. In order to prevent people from accessing content which could inspire them to bring about change, regimes soon found that a cheaper and more effective way was already available: flooding the Internet with gargabe content like entertainment sites, porn, etc. When one is overwhelmed by this content one is less prone to engage in discussions and debates on how to change the world.
The question arises, given the focus of this essay on corporate mind control, how does this method developed by regimes relate to the corporate agenda? It relates indirectly. Think about a motivated employee who thinks she can promote her ideas and bring about change in her organisation. What will a change-resistant organisation do? As we have seen above, it will no longer try to formally forbid this. Quite to the contrary, the organisation will pay lip service to innovation and invite proactive employees to check on the intranet what are the processes made available to submit proposals. This information will be buried in a sea of content, with primitive search functionality and the proactive employee will have to check hundreds of hits one by one manually, in a never-ending endeavour. Very soon more mundane tasks will take priority and divert this employee’s effort to tasks closely related to “how” questions (see above), and the time for proactivity will soon be over.
Misuse of Variable Compensation
There are very good reasons why a percentage of the total compensation can be variable. As I did above, I will not articulate here on the good uses of this practice. My focus is on how a malicious use of variable compensation is part of the tool set of the professional mind manipulator. When criteria for the recognition of variable compensation are set in a way which leaves room for interpretation, a manager can easily put the necessary pressure on her employees to obtain what she wants. Although employees are often advised to base their spend on fixed compensation and use variable compensation on non critical things or services, most people do otherwise. If the variable part of their compensation should be reduced, they may have very practical issues, like paying installments, a leasing, or failing to go on holiday. Giving a manager or a handful of individuals the power to decrease the salary of employees clearly gives them an extraordinary power to obtain exceptional performance. What is the problem with this technique of manipulation? Well, there are many. For example, some people focus on the objectives bound to the bonus, neglecting the rest. They become less collaborative and aim at achieving objectives in a formal way, not necessarily generating the expected value. Secondly, when people are treated like greedy individuals who only do something because otherwise they will get less salary, they will behave like ones. Appealing to the desires of the first order, like greed, is a sure way to make a good person behave like a fool.
Misuse of Gantt Charts
Gantt chart are a very popular representation of project plans. Despite the emergence and hype of agile methods, which are based on entirely different concepts, many enterprises still use Gantt charts because internal processes have been shaped over decades based on traditional project management practices. According to Wikipedia,
A Gantt chart is a type of bar chart, devised by Henry Gantt in the 1910s, that illustrates a project schedule. (…) One of the first major applications of Gantt charts was by the United States during World War I, at the instigation of General William Crozier.
source: “Gantt chart”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Gantt_chart
Gantt charts can be very effective and are a powerful tool when it comes to planning activities like the ones for which they were first introduced. Clearly, planning the activities of the army and planning knowledge work is not exactly the same thing. Part of the equivocation is innocent in its nature: thinking that the advancement of tasks is proportional to the effort invested into it, and the time needed to complete them is inversely proportional to the resources allocated. This is probably true if one builds a wooden table. At least, to an extent. But if one is trying to find an efficient algorithm to solve a problem, this is usually not true. The professional manipulator transforms a problem to solve in a plan, and then describes the solution to the problem in terms of such a plan. Having transformed a problem in its representation, the manipulator feels legitimised to drag tasks here and there, and think (or want others to think) that the corresponding activities can also be completed sooner or later, correspondingly. However, this is blatantly false, as the nine women paradox explains very well:
Misuse of Time Management
Let us start with defining what is Time Management:
Time management is the act or process of planning and exercising conscious control over the amount of time spent on specific activities, especially to increase effectiveness, efficiency or productivity. (…) The major themes arising from the literature on time management include the following:
- Creating an environment conducive to effectiveness
- Setting of priorities
- Carrying out activity around prioritization.
- The related process of reduction of time spent on non-priorities
- Incentives to modify behavior to ensure compliance with time-related deadlines.
It is a meta-activity with the goal to maximize the overall benefit of a set of other activities within the boundary condition of a limited amount of time, as time itself cannot be managed because it is fixed.
source: “Time management”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Time_management
While it is certainly true that, being time a finite resource, only a number of tasks can be done in any given finite period, that does not imply that people can be made to achieve more by switching tasks continuously based on a set of activities having ever-changing priorities. The human brain is simply not a CPU: context switch proves extraordinarily expensive as a mental process. When knowledge workers are focussed on their tasks and have maximum efficiency, they are in a so-called state of flow.
In positive psychology, flow, also known as the zone, is the mental state of operation in which a person performing an activity is fully immersed in a feeling of energized focus, full involvement, and enjoyment in the process of the activity. In essence, flow is characterized by complete absorption in what one does.
source: “Flow (psychology)”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Flow_(psychology)
Whenever a knowledge worker is interrupted, this state of flow ceases and it takes a certain amount of time to be re-established. The time required to get again into the state of flow following an interruption, is one of the reasons why misuse of time management actually reduces efficiency and efficacy, rather than increase them. And one can only undergo a number of cycles before her efficiency is completely spoiled for the whole day.
Professional manipulators use Time Management as an excuse to abuse their victims, so that they can interrupt them continuously whenever they need or want to have something immediately done at the expense of others. They will use a changed priority as a justification, forgetting or neglecting the fact that urgency and importance are two distinct and different things.
Emotional Techniques
Foment Perpetual Fear of Losing Job
In a job market shaped by the tenets of neo-liberalism, people are constantly compared with professionals from all around the world. Nobody is so good in her profession to be safe, when compared with professionals on a global scale. There is always someone who is better, cheaper, younger, has a better health and is more ambitious and driven to take anyone’s job. Companies restructure not only when they do bad but, increasingly, when they make good results. People are constantly confronted with cost cutting, digitization (see my essay The Dark Side of Digitization ), increasing use of Artificial Intelligence, etc. The effect on employees is that everyone feels replaceable. If one says no to a request, however irrational, someone else will immediately be ready to take her job. When forces like the above are used to intentionally foment fear of losing jobs, this is a mind control technique.
The Superman CEO
Years ago I was impressed to see a CEO call employees by their first name in occasion of a business party. He would address people like if he truly knew them and would ask questions like if he cared for what they were doing. That was an amazing thing. It had a great effect on me and I thought this was genuine. Years after, I met another CEO, who prided himself of having learnt Italian pretty fast and amazingly well. It was a remarkable achievement and employees went saying that they might not have been able to do the same. This CEO had an image like a super man. Employees started thinking, “there’s a reason why he is the CEO and I’m not, if he can learn a language in no time, God only knows what else he can do. He is cleverer than us, he is gifted.”
Year after year I have known a lot more CEOs and I have noticed that this is a pattern. While it may certainly be the case that most CEOs are indeed very gifted and smart individuals, probably well above the average, it is also true that some seem to have a clear urge to prove this alleged superiority with spectacular demonstrations like the above. When abilities are showcased in a very spectacular way, this is a form of manipulation and mind control. It is intended at creating the myth that the company is guided by extraordinary individuals and their decisions must just be trusted, even when not understood. The subliminal message is that there’s a reason why such decisions may seem irrational sometimes: it is that ordinary people like you and I can’t just understand them. The argument goes, “in the same way as we can’t remember the first name of all our colleagues (neither they really can, by the way) or learn another language so fast, we can’t just grasp the depth and full meaning of their decisions because we are not as smart as they are.”
Forbid Errors
Some organisations pursue practices which aim at forbidding errors. I remember a colleague managing a technical team shouting to them “this quarter you have to achieve the zero-ticket objective, understand!!!??”. Management practices like this have the objective to keep people focusing of the “how” questions (see above), and forget the “what” or “why” questions. When people cannot make a mistake they cannot innovate, cannot learn, cannot be truly proactive. All they can do is work like monkeys, day in and out.
Disconnection of Personal Contribution from Outcome
Human beings need to have feedback on their work. When a job is well done, normal people like this to be recognised. When negative feedback is received, one likes to be able to understand what went wrong, in order to be able to improve and do better next time. A mind control technique is based on the idea to make the connection between individual contribution and result opaque, so that people can no longer claim recognition for a job well done and can, at the same time, be blamed if something went wrong, even if they did not have anything to do with it. Tasks are defined in such a way that no individual contribution can easily or directly be linked to the overall outcome. Everything becomes “a team exercise”, with the implication that anyone in the team could have been replaced, and the same result still be achieved. The only way one can try to defend themselves from this, is to try to work on tasks whose deliverable has a clear value even when evaluated individually.
Prevent Formation of Consent (aka Divide and Conquer)
A family of manipulation techniques has the objective to prevent formation of consent. The reason is obvious: if a minority is to rule the majority, the most dangerous thing is when people gain awareness of having like interests and stakes in the situation. Because, if they do, they can join forces, and bring about change. But the ruling minority does not want this to happen. Therefore, it engages in a series of manipulation techniques which I will refer to as divide and conquer.
Competition
An example is fostering competition between individuals, teams, locations, etc. The alleged purpose is to stimulate healthy energies with the intention to let the best ideas emerge. The actual effect is oftentimes that people reduce or stop collaboration, pursue personal gratification instead of team objectives, try to claim ownership of achievements, cast a dark light on less talented individuals in order to shine better, and engage in a multitude of variations of rogue behaviour.
Forced Bell curves
This techniques is canny and sophisticated in the way it achieves deception. The idea is sometimes articulated along these lines. “Since there is statistical evidence that the performance of individuals in teams and organisations is distributed like a Bell curve, there is no reason, (true believers say), while the performance of your particular team should violate this scientific truth. Science in person tells us that performance has a Bell distribution: who are you, poor manager, to challenge this dogma?!”
This idea is plagued by many conceptual and pragmatic issues. The conceptual issue is that statistics is about big numbers. It may actually be true that in an organisation with 150’000 employees, performance overall is distributed like a Bell curve. But no mathematical law, and not even common sense, mandates that this be the case given any arbitrarily small subset of the overall sample space. In other words, if a manager has a team of six people, it is usually not the case that there has to be a complete idiot, two average individuals, two slightly smarter guys, and a genius. Enforcing Bell curves on arbitrarily small teams is like asking a player to use six dices: one with only ones, the second with only twos, … and the sixth one with only sixes, to make sure that using them one by one, the result will abide by the holy tenets of the Bernoully distribution. Only a madman would do that. But that is still a current management practice in a lot of companies nowadays. And people are tricked into believing it’s true, because it is allegedly based on statistics, which is assumed infallible like all branches of mathematics. But nobody should be allowed to claim mathematical truths without even grasping the basics. And if they do and still claim this technique is good, they are doing it maliciously, knowing to be tricking people.
Get Creative Contribution from Consultants, not Employees
An effective way to control individuals is to keep them constantly in a status of dis-empowerment. An instance of this technique is to give all creative work to consultants and treat employees like people who cannot possibly come out with innovative ideas. When people are treated like children, they will behave like ones.
Reference Letter/Work Certificate
A very common mind control technique is the practice which requires new employees to provide a reference letter from their previous employer. Knowing that your current employer will one day write a reference letter for you when you will leave (you want it or not), gives the employer an extraordinary power to limit the range of acceptable behaviour from you. If they ask you to work on a weekend and you would rather like to celebrate your daddy’s 80th birthday, they may write that you are not “flexible” or do not understand client priorities. And so on and so forth. In countries like Switzerland, the work certificate is particularly sophisticated because employers do not usually write negative statements. Instead, they omit to write positive statements. There exists a code, known by HR departments, which allows them to read between the lines in ways that no other reader can understand. For example, if they write an otherwise positive certificate, but omit the sentence “It is with regret that we received his resignations”, what they really mean is that that person may indeed be good and talented, but did not match their preferred behavioral cliche (maybe was too innovative or proactive), and they are not so displeased that she is leaving. On the receiving side, this apparently positive certificate will be interpreted as, “this is a smart guy, but she is going to create us headaches. Better get a less smart individual who stays quiet in her corner. If we should really need skills, we will take a consultant instead.”
Misuse of Lifelong Certifications
Another effective way to keep people quiet and focussed on the “how” questions, it to keep them busy learning some new technical tricks all the time. Getting certifications is a very good way of acquiring new skills and it is particularly useful in the current competitive job market. Certifications are usually required to technical specialists, less commonly to managers, especially senior managers.
When certifications are bound to promotions and professional models, there can be at least two effects. The first one is that there is more transparency in the promotion criteria, and this is clearly positive. The second one is that a manipulative manager can keep raising the bar, so that technical specialists are constantly in a condition of artificial deficiency. They will always lack a certification or two to be promoted, or even to keep their current band. To make things worse, modern certifications expire, and individuals have the burden to keep renewing them all the time. In addition to day job, people are constantly required to refresh their quickly obsolescent technical skills, and re-certify. These certifications are demanding and take a lot of time, usually in the evenings or weekends. When people are constantly busy certifying and proving themselves, they will not have the mindset, or simply the time, to seek new ways to change the world.
Conclusions
In this essay I have introduced the topic of corporate mind control. This is an evolving set of techniques used by a minority to control the majority. These techniques are aimed at limiting the set of acceptable behaviour, neutralise genuinely innovative ideas, disincentivise proactivity while claiming the contrary, and optimise profitability or other objectives through domination. These techniques are used by some corporations in various degrees. The range is from almost innocuous to very unethical. There is no such a thing as a corporate ranking in this regard. Or, at least, not one that I am aware of. The reason why I have researched this topic is that I argue that these techniques are unethical, because they violate the Kantian principle:
“Act in such a way that you treat humanity, whether in your own person or in the person of any other, never merely as a means to an end, but always at the same time as an end.”
— Immanuel Kant, Grounding for the Metaphysics of Morals
What this principle really means is subject to philosophical inquiry (see, for example http://philosophy.fas.nyu.edu/docs/IO/1881/scanlon.pdf). However, for the sake of my argument, we need not pursue sophisticated philosophical research. We only need to understand that human beings have priorities, intentions, ambitions, values, emotions, potential, limits, a need for social interactions, a sense of justice, self-esteem, etc. Therefore, they are very different from other “resources” utilised by corporations to produce goods or offer services. Mind control techniques are aimed at limiting the expression of the natural endowment of people, so that they pursue exclusively what is required to them to achieve goals and accomplish tasks defined by someone else. Extreme uses of these techniques deprive people of their dignity, because they are not treated also as ends, but only as a means to an end.
The techniques described in this essay have been developed over time and are utilised by all sorts of organisations, ranging from private enterprises, to political parties and regimes. This latter kind of organisation excels in use of media control, which is a subject not covered in this essay, because it has less relevance to private corporations. This is a separate topic very well covered, for example in:
- Media Control, Second Edition: The Spectacular Achievements of Propaganda (Open Media Series), Sep 3, 2002, by Noam Chomsky
I hope to have stimulated some constructive meditations on this important topic, with this admittedly peculiar essay, and I will be keen on receiving feedback. Thank you for reading.
References
T. Albrighton, “Twenty business metaphors and what they mean”. Retrieved December 21st, 2016, from http://www.abccopywriting.com/2013/03/18/20-business-metaphors-and-what-they-mean
N. Chomsky, 2002, “Media Control, Second Edition: The Spectacular Achievements of Propaganda” (Open Media Series)
I. Kant, “Grounding for the Metaphysics of Morals”
E. Morozov, 2012, “The Net Delusion: The Dark Side of Internet Freedom”
C. Newton, “The Five Communication Styles”. Retrieved December 21st, 2016, from
http://www.clairenewton.co.za/my-articles/the-five-communication-styles.html, accessed on 21 December 2016
(n.d). “Flow (psychology)”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Flow_(psychology)
(n.d). “Gantt chart”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Gantt_chart
(n.d). “Linguistic Relativity”. Retrieved January 4th, 2017, from https://en.wikipedia.org/wiki/Linguistic_relativity
(n.d). “Metaphor”. Retrieved December 21st, 2016, from https://www.merriam-webster.com/dictionary/metaphor
(n.d). “Metaphor Examples”. Retrieved December 21st, 2016, from http://examples.yourdictionary.com/metaphor-examples.html
(n.d). “Time management”. Retrieved January 14th, 2017, from https://en.wikipedia.org/wiki/Time_management
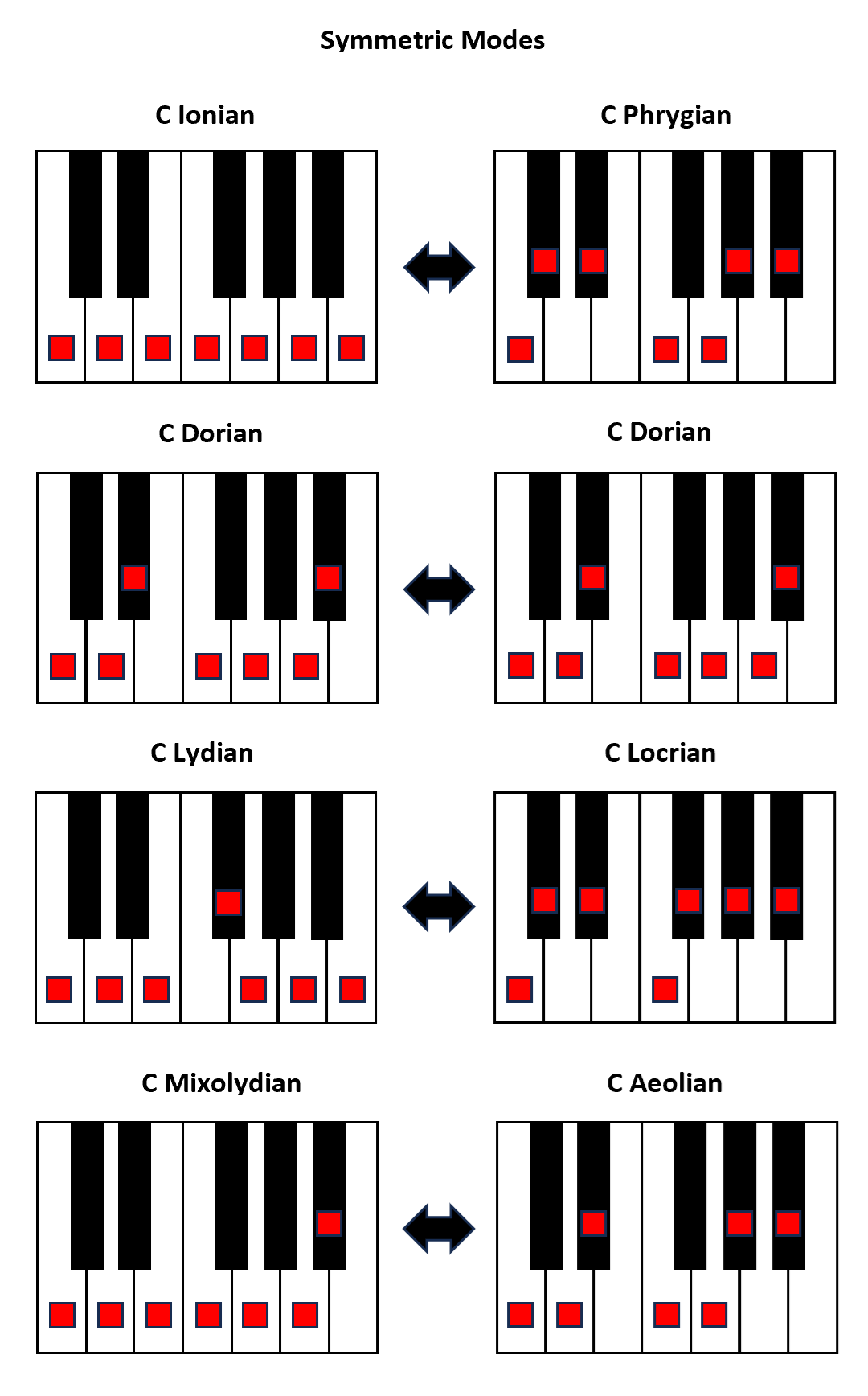
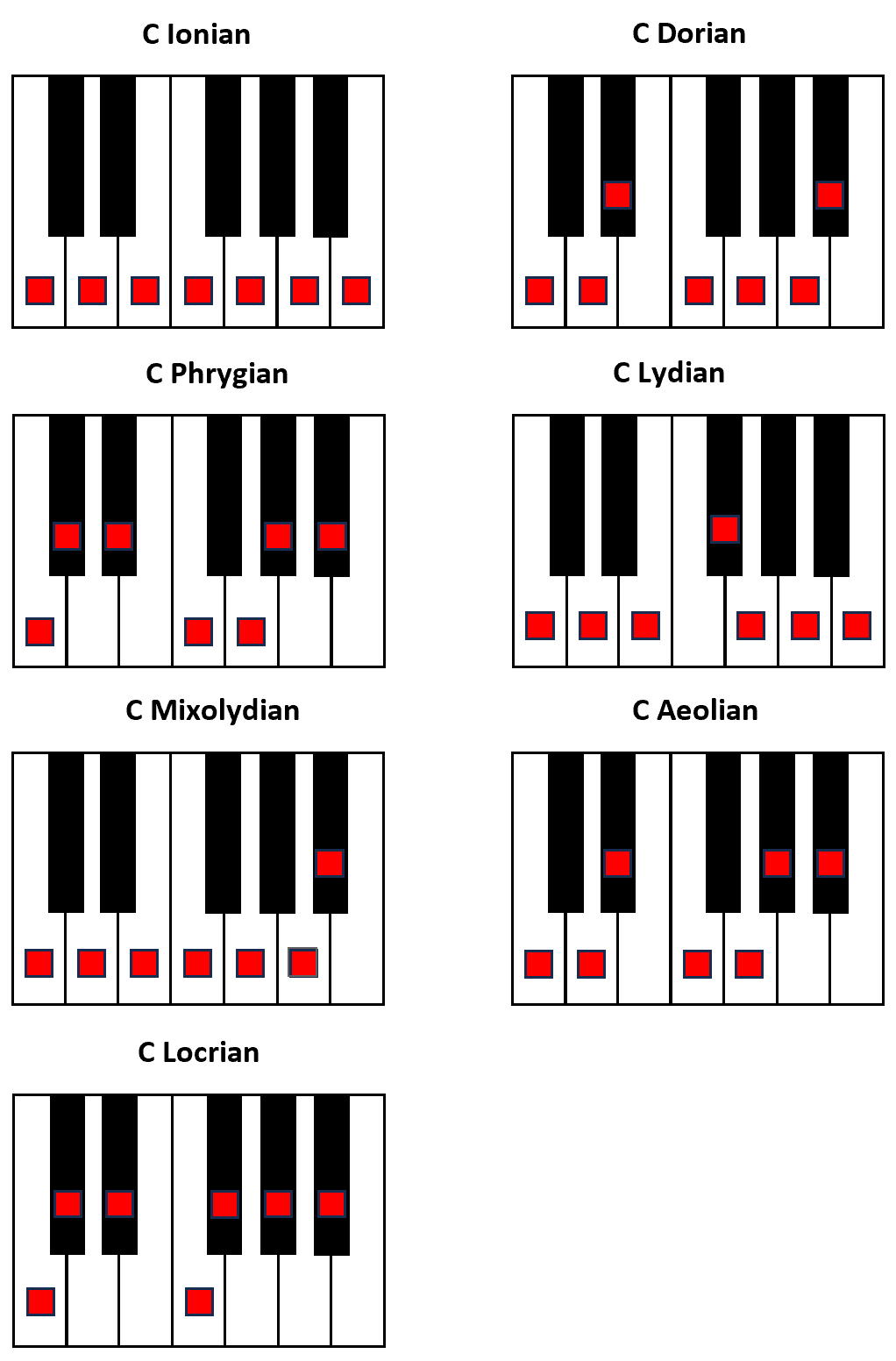





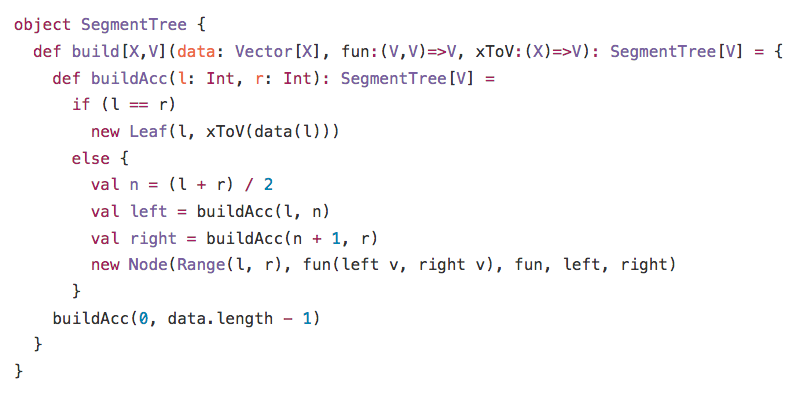



 In consideration of the above, it is easy to see that Application Testing is a particular instance of a more general mathematical problem: Hypothesis Testing. As such, it can be tuned to maximise its reliability either in terms of false positives or false negatives, but not both.
In consideration of the above, it is easy to see that Application Testing is a particular instance of a more general mathematical problem: Hypothesis Testing. As such, it can be tuned to maximise its reliability either in terms of false positives or false negatives, but not both.












{kind=link}
{kind=link}
{kind=link}
{kind=link}