 [Wikimedia]
[Wikimedia]
Introduction
The topic of automation has been revamped in the financial industry following the recent hype on industrialization of IT and lean banking. The rationale of the idea is that there are tasks which are better taken care of by automatons than by humans. This kind of tasks are composed by actions which are executed iteratively, and the quality of their outcomes can be negatively affected by even the smallest operational mistake. An interesting proportion of tests belong to this category. Not all of them, of course, because human intellect can still excel in more creative testing endeavours, like exploratory testing, to give just an example. But other kinds of tests, like regression-tests, would make a very good candidate for automation. Practitioners and managers know all too well that a well-rounded battery of regression tests can indeed prevent defects from being introduced in a new release with demonstrable positive effects on quality. But they also know that manual regression testing is inefficient, error prone, and expensive. Therefore, awareness is raising on the necessity to pursue an increase in the degree of test automation. In this essay I will argue that, before thinking about tooling, solutions, and blueprints, there is a key success factor that must be addressed: avoidance of the data bottleneck. I will first explain what it is, and why it can jeopardize even the most promising automation exercise. After that, I will introduce an architecture which can tackle this issue, and I will show that this approach will bring additional advantages along the way. I will now start the exposition introducing the topic of the data bottleneck.
The Data Bottleneck
If we make an abstraction exercise, we can see testing as a finite state automaton. We start from a state {s1} and after executing a test case TC1 we leave the system in state {s2}. A test case is a transition in our conceptual finite state diagram.

In order to be able to execute a test case, the initial state {s1} must satisfy some pre-conditions. When the test case is executed, ending state {s2} may or may not satisfy the post conditions. In the former case we say that the test case has succeeded; in the latter case we say that it has failed. Now, what does this have to do with automation? An example will clarify it. Let us consider the case of a credit request submitted by a client of a certain kind (e.g. private client, female). The pre-conditions of the test case require that no open credit request can exist for a given client when a new request is submitted. From the diagram above we see that there is no transition between states {s2} and {s1}. What does it mean? It means that business workflows are not engineered to be reversible. If the test case creates a credit request and it fails, there is no way to execute it again, because no new business case can be created in the application for this client, until the open request is cancelled. Now, there are cases in which the application can actually execute actions which recover a previous state. But in the majority of cases, this is not possible. In banking, logical data deletion is used instead of physical deletion. Actions are saved in history tables recording a timestamp and the identity of the user, for future reference by auditors. In cases like this, the initial state of a test case cannot be automatically recovered. Sometimes, not even manually. What one would need, is a full database recovery to an initial state where all test cases can be re-executed. This is the only way; other approaches to data recovery are not viable because of the way applications are designed and of applicable legislation.
Above we have seen that data recovery is a key pre-condition for automation. Now we will see why legacy environments are oftentimes an impediment to tackling this issue efficiently. Oftentimes, business data of a financial institution is stored in a mainframe database. And when it is not in a mainframe, the odds are, it is in an enterprise-class database, such as Oracle. What do an Oracle database on Unix/Linux, and a DB2 on a mainframe have in common? Technology-wise very little. Cost-wise, a lot: neither one comes for cheap. The practical implication is that database environments made available for testing are only a few, and they must be shared among testing teams. This makes it impracticable to make available automatic database recovery procedures, because of the synchronization and coordination required. What happens in reality is that test engineers have to carefully prepare their test data, hoping that no interference from their colleagues will affect their test plan. And what is worst, after they are finished with their tests, the data is no longer in a condition suitable for re-execution of the same battery of test cases. Another round of manual data preparation is required.
One may wonder if it is indeed impossible to reduce the degree of manual activity involved. The point is that so long as access to databases is mediated by applications, and applications obey by the business workflow rules (and applicable legislation), recoverability of data is not an option. Are we indeed stuck? Isn’t it possible to achieve automatic data recovery without breaking the secure data access architecture? My contention is that there is indeed a viable solution to this problem. The solution is outlined in the following section.
Proposed Solution: On-Demand Synthetic Test Environments
Automated tests take place in synthetic environments, that is, environments where no client data is available in clear. Therefore, the focus of this solution will be on these environments, which are the relevant ones when it comes to issues of efficiency, cost-optimisation, regressions and, ultimately, quality.
The safest way to recover a database to a desired consistent state is using snapshots. A full snapshot of a database in a consistent state is taken and this “golden image” is kept as the desired initial state of a battery of automated tests. Using the finite state representation, we can describe this concept in the following way:
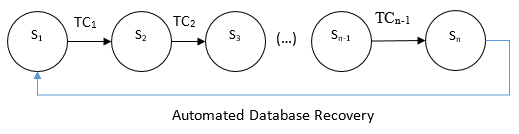
The diagram shows that any time a battery of automated test cases terminates, it can be executed again and again, just by recovering the initial desired state. To be more precise, the recovery procedure can take place not only at the end of the test battery, but at any desired intermediate state. This is particularly useful when a test case fails, and the battery must be re-executed after a fix is released. The diagram can be amended like this:

So, we have solved the problem of recovering the database to a desired consistent state which enables automatic (and manual) re-execution of test-cases. Is this all? What if other test engineers are also working on the same database environment? What would be the effect on their test case executions if someone else, inadvertently, swept their data away through the execution of an automatic database recovery procedure? It would simply be catastrophic, to say the least. This would bring about major disruption. How to fix this problem? What is needed is a kind of “sandboxing”: environments should be allocated so that only authorised personnel can run their test cases against the database, and no one else. Only the owner of one such environment should be in a position to order the execution of an automatic database recovery procedure. How can this be achieved? An effective way to do it is by offering on-demand test environments which can be allocated temporarily to a requestor. This sounds very much like private cloud. The below are the key attributes of an ideal solution to the on-demand test environment problem:
- Test environments shall be self-contained.
Applications, data and interfaces shall be deployed as a seamlessly working unit
- Allocation of test environments shall be done using a standard IT request workflow.
For example, opening a ticket in ServiceNow or what have you
- Test environments are allocated for a limited period of time.
After the allocation expires, servers are de-allocated. After a configurable interval, data is destroyed.
- During the whole duration of the environment reservation, an automatic database recovery procedure shall be offered.
This procedure may be executed by IT support whenever a request is submitted using a standard ticket. An internal Operational Level Agreement shall be defined. For example, full-database recovery is executed within a business day of the request.
- The TCO of the solution shall be predictable and flat with respect to the number of environments allocated.
Traditional virtual environments are allocated indefinitely and can easily become expensive IT zombies. Zombie environments still consume licenses, storage and other computing resources. Conversely, the solution proposed prevents these zombie environments from originating in the first place.
The logical representation of the proposed solution infrastructure is the following.

To sum up, these are the advantages of the proposed approach:
- It enables full test automation, making it truly possible to re-execute batteries of test cases using an automatic database recovery procedure in sand-boxed database instances.
- It gives 100% control of TCO and allows to keep testing spend on IT within defined limits.
- It allows to attribute testing spend to projects with high precision.
- It increases overall quality of testing results
- It eliminates cases of interference among independent test runs.
- It allows to anticipate involvement of test teams in the software life cycle.
- It saves infrastructure costs because computing clouds allow for transparent workload distribution, with the effect of running more (virtual) servers on the same physical infrastructure.
Conclusions
In this essay I have articulated the data bottleneck problem relating to test automation. First, I have given a general introduction to the topic. Second, I have explained why this problem may put in jeopardy test automation initiatives. Last, I have proposed a solution based on the concept of on-demand test automation environments and I have shown why I believe this is the way forward. The interested reader can contact me for sharing feedback or delving deeper in the discussion.
References
Wikimedia, 2015, https://commons.wikimedia.org/wiki/File:Buckeye_automatic_governor_%28New_Catechism_of_the_Steam_Engine,_1904%29.jpg, accessed 1 June 2015

{kind=link}